The best open source software for data storage and analytics
InfoWorld’s 2018 Best of Open Source Software Award winners in databases and data analytics















The best open source software for data storage and analytics
Nothing is bigger these days than data, data, data. We have more data than ever before, and we have more ways to store and analyze it—SQL databases, NoSQL databases, distributed OLTP databases, distributed OLAP platforms, distributed hybrid OLTP/OLAP platforms. Our 2018 Bossie winners in databases and data analytics platforms include innovators in stream processing as well.
[ InfoWorld presents the Best of Open Source Software Awards 2018: The best open source software for software development. | The best open source software for cloud computing. | The best open source software for data storage and analytics. | The best open source software for machine learning. ]
Apache Spark
While cooler kids have come to town, Apache Spark is still the center of the data analytics universe. If you’re doing distributed computing, data science, or machine learning, start here. With the release of Apache Spark 2.3 in February, Spark has continued to develop, integrate, and augment its structured streaming API. Additionally, there is now a scheduler for Kubernetes, making it easier to run Spark on the container platform directly. Overall the current Spark release feels like it has been greased, tuned, and had some polish rubbed on the chrome.
— Andrew C. Oliver
Apache Pulsar
Developed by Yahoo and now an incubating Apache project, Apache Pulsar is going for the crown of messaging that Apache Kafka has worn for many years. Apache Pulsar offers the potential of faster throughput and lower latency than Apache Kafka in many situations, along with a compatible API that allows developers to switch from Kafka to Pulsar with relative ease.
But perhaps the biggest advantage of Apache Pulsar is that it offers a much more streamlined and robust set of operational features than Apache Kafka, especially in terms of addressing observability, geo-replication, and multi-tenancy concerns. Enterprises that have felt the pains of operating large Apache Kafka clusters may find Apache Pulsar a breath of fresh air.
— Ian Pointer
Apache Beam
The distinction between batch processing and stream processing has, for years now, been fading away. Batches of data get smaller to become micro-batches, which, as they approach batches of one, become streaming data. A number of different processing architectures have attempted to map this shift in thinking into a programming paradigm.
Apache Beam is Google’s answer to the problem. Beam combines a programming model and several language-specific SDKs that allow for the definition of data processing pipelines. Once defined, those pipelines can be executed on a variety of different processing frameworks such as Hadoop, Spark, or Flink. When writing a data-intensive application (and whose application isn’t data-intensive these days?), Beam should be on your short list for building data processing pipelines.
— Jonathan Freeman
Apache Solr
While mainly thought of as a search engine built on the underlying Lucene indexing technology, Apache Solr is in essence a text-oriented document database. In fact it is a great one. Whether you’re trying to find a needle in a haystack or run a spatial query, Solr is here for you.
With the recent releases in the Solr 7 series, the platform is lightning fast even for more analytical queries. You can now join scores of documents and return results in under a second. There is improved support for log and event data. Disaster recovery (CDCR) is now bidirectional. And Solr’s new auto-scaling feature allows for simple management as the load on a cluster grows. Because achieving balance is a goal for server software too!
— Andrew C. Oliver

JupyterLab
JupyterLab is the next generation of Jupyter, the venerable web-based notebook server beloved by data scientists everywhere. Three years in the making, JupyterLab is a complete reimagining of the notebook concept, allowing things like drag-and-drop reordering of cells, tabbed notebooks, live preview of Markdown editing, and a revamped extension system that makes integrating with other services like GitHub a breeze. Expect to see JupyterLab reach a stable 1.0 release towards the end of 2018, and data science to get a bit of a facelift going into 2019.
— Ian Pointer

KNIME Analytics Platform
The KNIME Analytics Platform is open source software for creating data science applications and services. It features a drag-and-drop-style graphical interface for creating visual workflows, and also supports scripting in R and Python, machine learning, and connectors to Apache Spark. KNIME currently has about 2,000 modules that can be used as nodes in workflows.
There is also a commercial version of KNIME. This adds extensions for increasing productivity and enabling collaboration. Nonetheless, the open source KNIME Analytics Platform has no artificial limitations, and is able to handle projects with hundreds of millions of rows.
— Martin Heller
CockroachDB
CockroachDB is a distributed SQL database built on top of a transactional and consistent key-value store. It is designed to survive disk, machine, rack, and even data center failures with minimal latency disruption and no manual intervention. In my January 2018 review of CockroachDB v1.13, I gave the product five stars, but also noted it was still missing many features. That’s changed.
The arrival of CockroachDB v2.0 in April brought significant performance improvements, expanded the product’s PostgreSQL compatibility by adding support for JSON (among other types), and provided functionality for managing multi-regional clusters in production. On the roadmap for CockroachDB v2.1 are a cost-based query optimizer (for an order of magnitude improvement in query performance), correlated subqueries (for ORMs), and better support for schema changes, plus encryption at rest in the Enterprise product.
— Martin Heller
Vitess
Vitess is a database clustering system for horizontal scaling of MySQL through generalized sharding, written mostly in the Go language. Vitess combines many important MySQL features with the scalability of a NoSQL database. Its built-in sharding features let you grow your database without adding sharding logic to your application. Vitess has been a core component of YouTube’s database infrastructure since 2011, and has grown to encompass tens of thousands of MySQL nodes.
Rather than using standard MySQL connections, which consume a lot of RAM and can limit the number of connections per node, Vitess uses a more efficient gRPC-based protocol. Plus Vitess automatically rewrites queries that hurt database performance, and takes advantage of caching mechanisms to mediate queries and prevent duplicate queries from simultaneously reaching your database.
— Martin Heller
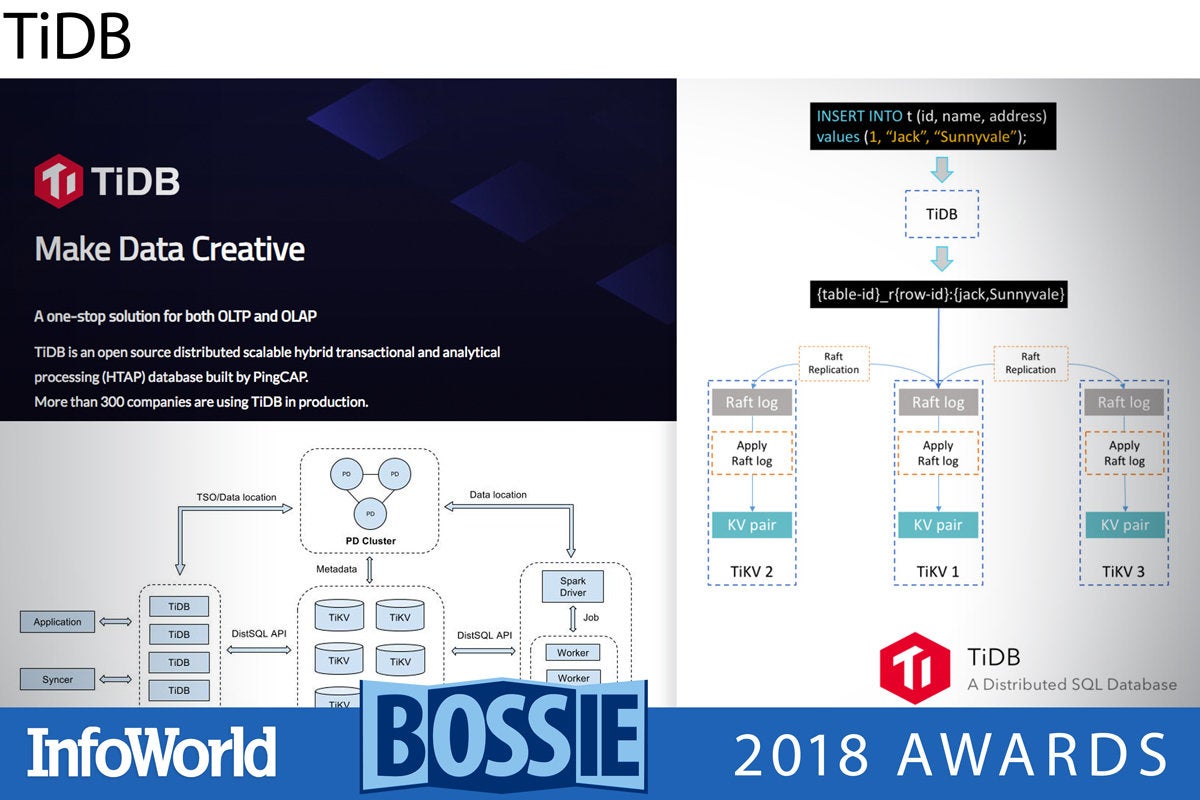
TiDB
TiDB is a MySQL-compatible, distributed, Hybrid Transactional and Analytical Processing (HTAP) database. It is built on top of a transactional key-value store and offers total horizontal scalability (by adding nodes) and continuous availability. Most early TiDB users were in China, as the developers are in Beijing. The TiDB source code is mostly written in the Go language.
The lowest layer of TiDB is RocksDB, a log structured key-value database engine from Facebook, written in C++ for maximum performance. Above that is a Raft consensus layer, a transaction layer, and eventually a SQL layer that supports the MySQL protocol.
— Martin Heller

YugaByte DB
YugaByte DB combines distributed ACID transactions, multi-region deployment, and support for Cassandra and Redis APIs, with PostgreSQL on the way. One huge improvement over Cassandra is that YugaByte is strongly consistent, while Cassandra is eventually consistent. YugaByte still outperforms open source Cassandra on the YCSB benchmarks, but not as much as the commercial version of Cassandra, DataStax Enterprise 6, which has tunable consistency. YugaByte is useful as a faster, more consistent, distributed Redis and Cassandra. It can also be used to standardize on a single database for multiple purposes, such as combining a Cassandra database with Redis caching.
— Martin Heller

Neo4j
Neo4j, the original graph database, is vastly more efficient than SQL or NoSQL databases for tasks that look at networks of related items, but the graph model and Cypher query language require learning. Neo4j recently proved itself valuable yet again in the analysis of Russian Twitter trolls, and of the ICIJ’s Panama Papers and Paradise Papers.
After 18 years of development, Neo4j is a mature graph database platform that you can run on Windows, MacOS, and Linux, in Docker containers, in VMs, and in clusters. Neo4j can handle very large graphs, even in its open source edition, and unlimited graph sizes in its enterprise edition. (The open source version of Neo4j is limited to one server.)
— Martin Heller

InfluxDB
InfluxDB is an open source time series database with no external dependencies. Designed to handle heavy write and query loads, it’s useful for recording metrics and events, and performing analytics. It runs on MacOS, Docker, Ubuntu/Debian, Red Hat/CentOS, and Windows. It has a built-in HTTP API, a SQL-like query language, and aims to answer queries in real-time, meaning less than 100ms.
— Martin Heller
Copyright © 2018 IDG Communications, Inc.